Вычислим в MS EXCEL дисперсию и стандартное отклонение выборки. Также вычислим дисперсию случайной величины, если известно ее распределение.
Сначала рассмотрим дисперсию , затем стандартное отклонение .
Дисперсия выборки
Дисперсия выборки (выборочная дисперсия, sample variance ) характеризует разброс значений в массиве относительно .
Все 3 формулы математически эквивалентны.
Из первой формулы видно, что дисперсия выборки это сумма квадратов отклонений каждого значения в массиве от среднего , деленная на размер выборки минус 1.
дисперсии выборки используется функция ДИСП() , англ. название VAR, т.е. VARiance. С версии MS EXCEL 2010 рекомендуется использовать ее аналог ДИСП.В() , англ. название VARS, т.е. Sample VARiance. Кроме того, начиная с версии MS EXCEL 2010 присутствует функция ДИСП.Г(), англ. название VARP, т.е. Population VARiance, которая вычисляет дисперсию для генеральной совокупности . Все отличие сводится к знаменателю: вместо n-1 как у ДИСП.В() , у ДИСП.Г() в знаменателе просто n. До MS EXCEL 2010 для вычисления дисперсии генеральной совокупности использовалась функция ДИСПР() .
Дисперсию выборки
=КВАДРОТКЛ(Выборка)/(СЧЁТ(Выборка)-1)
=(СУММКВ(Выборка)-СЧЁТ(Выборка)*СРЗНАЧ(Выборка)^2)/ (СЧЁТ(Выборка)-1)
– обычная формула
=СУММ((Выборка -СРЗНАЧ(Выборка))^2)/ (СЧЁТ(Выборка)-1
) –
Дисперсия выборки равна 0, только в том случае, если все значения равны между собой и, соответственно, равны среднему значению . Обычно, чем больше величина дисперсии , тем больше разброс значений в массиве.
Дисперсия выборки является точечной оценкой дисперсии распределения случайной величины, из которой была сделана выборка . О построении доверительных интервалов при оценке дисперсии можно прочитать в статье .
Дисперсия случайной величины
Чтобы вычислить дисперсию случайной величины, необходимо знать ее .
Для дисперсии случайной величины Х часто используют обозначение Var(Х). Дисперсия равна квадрата отклонения от среднего E(X): Var(Х)=E[(X-E(X)) 2 ]
дисперсия вычисляется по формуле:

где x i – значение, которое может принимать случайная величина, а μ – среднее значение (), р(x) – вероятность, что случайная величина примет значение х.
Если случайная величина имеет , то дисперсия вычисляется по формуле:

Размерность дисперсии соответствует квадрату единицы измерения исходных значений. Например, если значения в выборке представляют собой измерения веса детали (в кг), то размерность дисперсии будет кг 2 . Это бывает сложно интерпретировать, поэтому для характеристики разброса значений чаще используют величину равную квадратному корню из дисперсии – стандартное отклонение .
Некоторые свойства дисперсии :
Var(Х+a)=Var(Х), где Х - случайная величина, а - константа.
Var(aХ)=a 2 Var(X)
Var(Х)=E[(X-E(X)) 2 ]=E=E(X 2)-E(2*X*E(X))+(E(X)) 2 =E(X 2)-2*E(X)*E(X)+(E(X)) 2 =E(X 2)-(E(X)) 2
Это свойство дисперсии используется в статье про линейную регрессию .
Var(Х+Y)=Var(Х) + Var(Y) + 2*Cov(Х;Y), где Х и Y - случайные величины, Cov(Х;Y) - ковариация этих случайных величин.
Если случайные величины независимы (independent), то их ковариация равна 0, и, следовательно, Var(Х+Y)=Var(Х)+Var(Y). Это свойство дисперсии используется при выводе .
Покажем, что для независимых величин Var(Х-Y)=Var(Х+Y). Действительно, Var(Х-Y)= Var(Х-Y)= Var(Х+(-Y))= Var(Х)+Var(-Y)= Var(Х)+Var(-Y)= Var(Х)+(-1) 2 Var(Y)= Var(Х)+Var(Y)= Var(Х+Y). Это свойство дисперсии используется для построения .
Стандартное отклонение выборки
Стандартное отклонение выборки - это мера того, насколько широко разбросаны значения в выборке относительно их .
По определению, стандартное отклонение равно квадратному корню из дисперсии :

Стандартное отклонение не учитывает величину значений в выборке , а только степень рассеивания значений вокруг их среднего . Чтобы проиллюстрировать это приведем пример.
Вычислим стандартное отклонение для 2-х выборок: (1; 5; 9) и (1001; 1005; 1009). В обоих случаях, s=4. Очевидно, что отношение величины стандартного отклонения к значениям массива у выборок существенно отличается. Для таких случаев используется Коэффициент вариации (Coefficient of Variation, CV) - отношение Стандартного отклонения к среднему арифметическому , выраженного в процентах.
В MS EXCEL 2007 и более ранних версиях для вычисления Стандартного отклонения выборки используется функция =СТАНДОТКЛОН() , англ. название STDEV, т.е. STandard DEViation. С версии MS EXCEL 2010 рекомендуется использовать ее аналог =СТАНДОТКЛОН.В() , англ. название STDEV.S, т.е. Sample STandard DEViation.
Кроме того, начиная с версии MS EXCEL 2010 присутствует функция СТАНДОТКЛОН.Г() , англ. название STDEV.P, т.е. Population STandard DEViation, которая вычисляет стандартное отклонение для генеральной совокупности . Все отличие сводится к знаменателю: вместо n-1 как у СТАНДОТКЛОН.В() , у СТАНДОТКЛОН.Г() в знаменателе просто n.
Стандартное отклонение
можно также вычислить непосредственно по нижеуказанным формулам (см. файл примера
)
=КОРЕНЬ(КВАДРОТКЛ(Выборка)/(СЧЁТ(Выборка)-1))
=КОРЕНЬ((СУММКВ(Выборка)-СЧЁТ(Выборка)*СРЗНАЧ(Выборка)^2)/(СЧЁТ(Выборка)-1))
Другие меры разброса
Функция КВАДРОТКЛ() вычисляет сумму квадратов отклонений значений от их среднего . Эта функция вернет тот же результат, что и формула =ДИСП.Г(Выборка )*СЧЁТ(Выборка ) , где Выборка - ссылка на диапазон, содержащий массив значений выборки (). Вычисления в функции КВАДРОТКЛ() производятся по формуле:

Функция СРОТКЛ() является также мерой разброса множества данных. Функция СРОТКЛ() вычисляет среднее абсолютных значений отклонений значений от среднего . Эта функция вернет тот же результат, что и формула =СУММПРОИЗВ(ABS(Выборка-СРЗНАЧ(Выборка)))/СЧЁТ(Выборка) , где Выборка - ссылка на диапазон, содержащий массив значений выборки.
Вычисления в функции СРОТКЛ () производятся по формуле:

Вариационный размах (или размах вариации) - это разница между максимальным и минимальным значениями признака:
В нашем примере размах вариации сменной выработки рабочих составляет: в первой бригаде R=105-95=10 дет., во второй бригаде R=125-75=50 дет. (в 5 раз больше). Это говорит о том, что выработка 1-й бригады более «устойчива», но резервов роста выработки больше у второй бригады, т.к. в случае достижения всеми рабочими максимальной для этой бригады выработки, ею может быть изготовлено 3*125=375 деталей, а в 1-й бригаде только 105*3=315 деталей.
Если крайние значения признака не типичны для совокупности, то используют квартильный или децильный размахи. Квартильный размах RQ= Q3-Q1 охватывает 50% объема совокупности, децильный размах первый RD1 = D9-D1охватывает 80% данных, второй децильный размах RD2= D8-D2 – 60 %.
Недостатком показателя вариационного размаха является, но что его величина не отражает все колебания признака.
Простейшим обобщающим показателем, отражающим все колебания признака, является среднее линейное отклонение
, представляющее собой среднюю арифметическую абсолютных отклонений отдельных вариант от их средней величины:
,
для сгруппированных данных ![]() ,
,
где хi – значение признака в дискретном ряду или середина интервала в интервальном распределении.
В вышеприведенных формулах разности в числителе взяты по модулю, иначе, согласно свойству средней арифметической, числитель всегда будет равен нулю. Поэтому среднее линейное отклонение в статистической практике применяют редко, только в тех случаях, когда суммирование показателей без учета знака имеет экономический смысл. С его помощью, например, анализируется состав работающих, рентабельность производства, оборот внешней торговли.
Дисперсия признака
– это средний квадрат отклонений вариант от их средней величины:
простая дисперсия![]() ,
,
взвешенная дисперсия .
.
Формулу для расчета дисперсии можно упростить:
Таким образом, дисперсия равна разности средней из квадратов вариант и квадрата средней из вариант совокупности: .
.
Однако, вследствие суммирования квадратов отклонений дисперсия дает искаженное представление об отклонениях, поэтому ее на основе рассчитывают среднее квадратическое отклонение
, которое показывает, на сколько в среднем отклоняются конкретные варианты признака от их среднего значения. Вычисляется путем извлечения квадратного корня из дисперсии:
для несгруппированных данных ,
,
для вариационного ряда
Чем меньше значение дисперсии и среднего квадратического отклонения, тем однороднее совокупность, тем более надежной (типичной) будет средняя величина.
Среднее линейное и среднее квадратичное отклонение - именованные числа, т. е. выражаются в единицах измерения признака, идентичны по содержанию и близки по значению.
Рассчитывать абсолютные показатели вариации рекомендуется с помощью таблиц.
Таблица 3 – Расчет характеристик вариации (на примере срока данных о сменной выработке рабочих бригады)
Число рабочих, |
Середина интервала, |
Расчетные значения |
|||||
Итого: |
|||||||
Среднесменная выработка рабочих:![]()
Среднее линейное отклонение:![]()
Дисперсия выработки:
Среднее квадратическое отклонение выработки отдельных рабочих от средней выработки:
.
1 Расчет дисперсии способом моментов
Вычисление дисперсий связано с громоздкими расчетами (особенно если средняя величина выражена большим числом с несколькими десятичными знаками). Расчеты можно упростить, если использовать упрощенную формулу и свойства дисперсии.
Дисперсия обладает следующими свойствами:
- если все значения признака уменьшить или увеличить на одну и ту же величину А, то дисперсия от этого не уменьшится:
 ,
,
 , то или
, то или 
Используя свойства дисперсии и сначала уменьшив все варианты совокупности на величину А, а затем разделив на величину интервала h, получим формулу вычисления дисперсии в вариационных рядах с равными интервалами способом моментов:
 ,
,
где – дисперсия, исчисленная по способу моментов;
h – величина интервала вариационного ряда;
– новые (преобразованные) значения вариант;
А– постоянная величина, в качестве которой используют середину интервала, обладающего наибольшей частотой; либо вариант, имеющий наибольшую частоту; 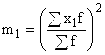 – квадрат момента первого порядка;
– квадрат момента первого порядка;
– момент второго порядка.
Выполним расчет дисперсии способом моментов на основе данных о сменной выработке рабочих бригады.
Таблица 4 – Расчет дисперсии по способу моментов
Группы рабочих по выработке, шт. |
Число рабочих, |
Середина интервала, |
Расчетные значения |
||
Порядок расчета:


- рассчитываем дисперсию:
2 Расчет дисперсии альтернативного признака
Среди признаков, изучаемых статистикой, есть и такие, которым свойственны лишь два взаимно исключающих значения. Это альтернативные признаки. Им придается соответственно два количественных значения: варианты 1 и 0. Частостью варианты 1, которая обозначается p, является доля единиц, обладающих данным признаком. Разность 1-р=q является частостью варианты 0. Таким образом,
хi |
|
Средняя арифметическая альтернативного признака![]() , т. к. p+q=1.
, т. к. p+q=1.
Дисперсия альтернативного признака
, т.к. 1-р=q
Таким образом, дисперсия альтернативного признака равна произведению доли единиц, обладающих данным признаком, и доли единиц, не обладающих этим признаком.
Если значения 1 и 0 встречаются одинаково часто, т. е. p=q, дисперсия достигает своего максимума pq=0,25.
Дисперсия альтернативного признака используется в выборочных обследованиях, например, качества продукции.
3 Межгрупповая дисперсия. Правило сложения дисперсий
Дисперсия, в отличие от других характеристик вариации, является аддитивной величиной. То есть в совокупности, которая разделена на группы по факторному признаку х, дисперсия результативного признака y может быть разложена на дисперсию в каждой группе (внутригрупповую) и дисперсию между группами (межгрупповую). Тогда, наряду с изучением вариации признака по всей совокупности в целом, становится возможным изучение вариации в каждой группе, а также между этими группами.
Общая дисперсия
измеряет вариацию признака у
по всей совокупности под влиянием всех факторов, вызвавших эту вариацию (отклонения). Она равна среднему квадрату отклонений отдельных значений признака у
от общей средней и может быть вычислена как простая или взвешенная дисперсия.
Межгрупповая дисперсия
характеризует вариацию результативного признака у
, вызванную влиянием признака-фактора х
, положенного в основу группировки. Она характеризует вариацию групповых средних и равна среднему квадрату отклонений групповых средних от общей средней : ,
,
где – средняя арифметическая i-той группы;
– численность единиц в i-той группе (частота i-той группы);
– общая средняя совокупности.
Внутригрупповая дисперсия
отражает случайную вариацию, т. е. ту часть вариации, которая вызвана влиянием неучтенных факторов и не зависит от признака-фактора, положенного в основу группировки. Она характеризует вариацию индивидуальных значений относительно групповых средних, равна среднему квадрату отклонений отдельных значений признака у
внутри группы от средней арифметической этой группы (групповой средней) и вычисляется как простая или взвешенная дисперсия для каждой группы: ![]() или
или ![]() ,
,
где – число единиц в группе.
На основании внутригрупповых дисперсий по каждой группе можно определить общую среднюю из внутригрупповых дисперсий
:
.
Взаимосвязь между тремя дисперсиями получила название правила сложения дисперсий
, согласно которому общая дисперсия равна сумме межгрупповой дисперсии и средней из внутригрупповых дисперсий:
Пример
. При изучении влияния тарифного разряда (квалификации) рабочих на уровень производительности их труда получены следующие данные.
Таблица 5 – Распределение рабочих по среднечасовой выработке.
№ п/п |
Рабочие 4-го разряда |
Рабочие 5-го разряда |
|||||
Выработка |
Выработка |
||||||
1 |
7 |
7-10=-3 |
9 |
1 |
14 |
14-15=-1 |
1 |
В данном примере рабочие разделены на две группы по факторному признаку х
– квалификации, которая характеризуется их разрядом. Результативный признак – выработка – варьируется как под его влиянием (межгрупповая вариация), так и за счет других случайных факторов (внутригрупповая вариация). Задача заключается в измерении этих вариаций с помощью трех дисперсий: общей, межгрупповой и внутригрупповой.
Эмпирический коэффициент детерминации показывает долю вариации результативного признака у
под влиянием факторного признака х
. Остальная часть общей вариации у
вызвана изменением прочих факторов.
В примере эмпирический коэффициент детерминации равен:![]() или 66,7 %,
или 66,7 %,
Это означает, что на 66,7% вариация производительности труда рабочих обусловлена различиями в квалификации, а на 33,3% – влиянием прочих факторов.
Эмпирическое корреляционное отношение
показывает тесноту связи между группировочным и результативными признаками. Рассчитывается как корень квадратный из эмпирического коэффициента детерминации:
Эмпирическое корреляционное отношение , как и , может принимать значения от 0 до 1.
Если связь отсутствует, то =0. В этом случае =0, то есть групповые средние равны между собой и межгрупповой вариации нет. Значит группировочный признак – фактор не влияет на образование общей вариации.
Если связь функциональная, то =1. В этом случае дисперсия групповых средних равна общей дисперсии (), то есть внутригрупповой вариации нет. Это означает, что группировочный признак полностью определяет вариацию изучаемого результативного признака.
Чем ближе значение корреляционного отношения к единице, тем теснее, ближе к функциональной зависимости связь между признаками.
Для качественной оценки тесноты связи между признаками пользуются соотношениями Чэддока.
В примере ![]() , что свидетельствует о тесной связи между производительностью труда рабочих и их квалификацией.
, что свидетельствует о тесной связи между производительностью труда рабочих и их квалификацией.
Однако только этой характеристики ещё не достаточно для исследования случайной величины. Представим двух стрелков, которые стреляют по мишени. Один стреляет метко и попадает близко к центру, а другой… просто развлекается и даже не целится. Но что забавно, его средний результат будет точно таким же, как и у первого стрелка! Эту ситуацию условно иллюстрируют следующие случайные величины:
«Снайперское» математическое ожидание равно , однако и у «интересной личности»: – оно тоже нулевое!
Таким образом, возникает потребность количественно оценить, насколько далеко рассеяны пули (значения случайной величины) относительно центра мишени (математического ожидания). Ну а рассеяние с латыни переводится не иначе, как дисперсия .
Посмотрим, как определяется эта числовая характеристика на одном из примеров 1-й части урока:
Там мы нашли неутешительное математическое ожидание этой игры, и сейчас нам предстоит вычислить её дисперсию, которая обозначается через .
Выясним, насколько далеко «разбросаны» выигрыши/проигрыши относительно среднего значения. Очевидно, что для этого нужно вычислить разности между значениями случайной величины и её математическим ожиданием :
–5 – (–0,5) = –4,5
2,5 – (–0,5) = 3
10 – (–0,5) = 10,5
Теперь вроде бы нужно просуммировать результаты, но этот путь не годится – по той причине, что колебания влево будут взаимоуничтожаться с колебаниями вправо. Так, например, у стрелка-«любителя» (пример выше)
разности составят ![]() , и при сложении дадут ноль, поэтому никакой оценки рассеяния его стрельбы мы не получим.
, и при сложении дадут ноль, поэтому никакой оценки рассеяния его стрельбы мы не получим.
Чтобы обойти эту неприятность можно рассмотреть модули
разностей, но по техническим причинам прижился подход, когда их возводят в квадрат. Решение удобнее оформить таблицей:
И здесь напрашивается вычислить средневзвешенное
значение квадратов отклонений. А это ЧТО такое? Это их математическое ожидание
, которое и является мерилом рассеяния:
![]() – определение
дисперсии. Из определения сразу понятно, что дисперсия не может быть отрицательной
– возьмите на заметку для практики!
– определение
дисперсии. Из определения сразу понятно, что дисперсия не может быть отрицательной
– возьмите на заметку для практики!
Вспоминаем, как находить матожидание. Перемножаем квадраты разностей на соответствующие вероятности (продолжение таблицы)
:
– образно говоря, это «сила тяги»,
и суммируем результаты:
Не кажется ли вам, что на фоне выигрышей результат получился великоватым? Всё верно – мы возводили в квадрат, и чтобы вернуться в размерность нашей игры, нужно извлечь квадратный корень. Данная величина называется средним квадратическим отклонением
и обозначается греческой буквой «сигма»:
Иногда это значение называют стандартным отклонением .
В чём его смысл? Если мы отклонимся от математического ожидания влево и вправо на среднее квадратическое отклонение:![]()
– то на этом интервале будут «сконцентрированы» наиболее вероятные значения случайной величины. Что мы, собственно, и наблюдаем:
Однако так сложилось, что при анализе рассеяния почти всегда оперируют понятием дисперсии. Давайте разберёмся, что она означает применительно к играм. Если в случае со стрелками речь идёт о «кучности» попаданий относительно центра мишени, то здесь дисперсия характеризует две вещи:
Во-первых, очевидно то, что при увеличении ставок, дисперсия тоже возрастает. Так, например, если мы увеличим в 10 раз, то математическое ожидание увеличится в 10 раз, а дисперсия – в 100 раз (коль скоро, это квадратичная величина) . Но, заметьте, что сами-то правила игры не изменились! Изменились лишь ставки, грубо говоря, раньше мы ставили 10 рублей, теперь 100.
Второй, более интересный момент состоит в том, что дисперсия характеризует стиль игры. Мысленно зафиксируем игровые ставки на каком-то определённом уровне , и посмотрим, что здесь к чему:
Игра с низкой дисперсией – это осторожная игра. Игрок склонен выбирать самые надёжные схемы, где за 1 раз он не проигрывает/выигрывает слишком много. Например, система «красное/чёрное» в рулетке (см. Пример 4 статьи Случайные величины ) .
Игра с высокой дисперсией. Её часто называют дисперсионной игрой. Это авантюрный или агрессивный стиль игры, где игрок выбирает «адреналиновые» схемы. Вспомним хотя бы «Мартингейл» , в котором на кону оказываются суммы, на порядки превосходящие «тихую» игру предыдущего пункта.
Показательна ситуация в покере: здесь есть так называемые тайтовые игроки, которые склонны осторожничать и «трястись» над своими игровыми средствами (банкроллом) . Неудивительно, что их банкролл не подвергается значительным колебаниям (низкая дисперсия). Наоборот, если у игрока высокая дисперсия, то это агрессор. Он часто рискует, делает крупные ставки и может, как сорвать огромный банк, так и програться в пух и прах.
То же самое происходит на Форексе, и так далее – примеров масса.
Причём, во всех случаях не важно – на копейки ли идёт игра или на тысячи долларов. На любом уровне есть свои низко- и высокодисперсионные игроки. Ну а за средний выигрыш, как мы помним, «отвечает» математическое ожидание .
Наверное, вы заметили, что нахождение дисперсии – есть процесс длительный и кропотливый. Но математика щедрА:
Формула для нахождения дисперсии
Данная формула выводится непосредственно из определения дисперсии, и мы незамедлительно пускаем её в оборот. Скопирую сверху табличку с нашей игрой:
и найденное матожидание .
Вычислим дисперсию вторым способом. Сначала найдём математическое ожидание – квадрата случайной величины . По определению математического ожидания
:
Таким образом, по формуле:
Как говорится, почувствуйте разницу. И на практике, конечно, лучше применять формулу (если иного не требует условие).
Осваиваем технику решения и оформления:
Пример 6

Найти её математическое ожидание, дисперсию и среднее квадратическое отклонение.
Эта задача встречается повсеместно, и, как правило, идёт без содержательного смысла.
Можете представлять себе несколько лампочек с числами, которые загораются в дурдоме с определёнными вероятностями:)
Решение
: Основные вычисления удобно свести в таблицу. Сначала в верхние две строки записываем исходные данные. Затем рассчитываем произведения , затем и, наконец, суммы в правом столбце:
Собственно, почти всё готово. В третьей строке нарисовалось готовенькое математическое ожидание: ![]() .
.
Дисперсию вычислим по формуле:
И, наконец, среднее квадратическое отклонение:
– лично я обычно округляю до 2 знаков после запятой.
Все вычисления можно провести на калькуляторе, а ещё лучше – в Экселе:
вот здесь уже трудно ошибиться:)
Ответ :
Желающие могут ещё более упростить свою жизнь и воспользоваться моим калькулятором (демо) , который не только моментально решит данную задачу, но и построит тематические графики (скоро дойдём) . Программу можно скачать в библиотеке – если вы загрузили хотя бы один учебный материал, либо получить другим способом . Спасибо за поддержку проекта!
Пара заданий для самостоятельного решения:
Пример 7
Вычислить дисперсию случайной величины предыдущего примера по определению.
И аналогичный пример:
Пример 8
Дискретная случайная величина задана своим законом распределения:

Да, значения случайной величины бывают достаточно большими (пример из реальной работы) , и здесь по возможности используйте Эксель. Как, кстати, и в Примере 7 – это быстрее, надёжнее и приятнее.
Решения и ответы внизу страницы.
В заключение 2-й части урока разберём ещё одну типовую задачу, можно даже сказать, небольшой ребус:
Пример 9
Дискретная случайная величина может принимать только два значения: и , причём . Известна вероятность , математическое ожидание и дисперсия .
Решение
: начнём с неизвестной вероятности. Так как случайная величина может принять только два значения, то сумма вероятностей соответствующих событий:
и поскольку , то .
Осталось найти …, легко сказать:) Но да ладно, понеслось. По определению математического ожидания:![]() – подставляем известные величины:
– подставляем известные величины:
![]() – и больше из этого уравнения ничего не выжать, разве что можно переписать его в привычном направлении:
– и больше из этого уравнения ничего не выжать, разве что можно переписать его в привычном направлении:![]()

или: ![]()
О дальнейших действиях, думаю, вы догадываетесь. Составим и решим систему:
Десятичные дроби – это, конечно, полное безобразие; умножаем оба уравнения на 10:
и делим на 2:
Вот так-то лучше. Из 1-го уравнения выражаем:![]() (это более простой путь)
– подставляем во 2-е уравнение:
(это более простой путь)
– подставляем во 2-е уравнение:
![]()
Возводим в квадрат
и проводим упрощения:
Умножаем на :
В результате получено квадратное уравнение
, находим его дискриминант:
– отлично!
и у нас получается два решения:
1) если ![]() , то
, то ![]() ;
;
2) если ![]() , то .
, то .
Условию удовлетворяет первая пара значений. С высокой вероятностью всё правильно, но, тем не менее, запишем закон распределения:
и выполним проверку, а именно, найдём матожидание:
Дисперсия — это мера рассеяния, описывающая сравнительное отклонение между значениями данных и средней величиной. Является наиболее используемой мерой рассеяния в статистике, вычисляемая путем суммирования, возведенного в квадрат, отклонения каждого значения данных от средней величины. Формула для вычисления дисперсии представлена ниже:
![]()
s 2 – дисперсия выборки;
x ср — среднее значение выборки;
n — размер выборки (количество значений данных),
(x i – x ср) — отклонение от средней величины для каждого значения набора данных.
Для лучшего понимания формулы, разберем пример. Я не очень люблю готовку, поэтому занятием этим занимаюсь крайне редко. Тем не менее, чтобы не умереть с голоду, время от времени мне приходится подходить к плите для реализации замысла по насыщению моего организма белками, жирами и углеводами. Набор данных, редставленный ниже, показывает, сколько раз Ренат готовит пищу каждый месяц:
Первым шагом при вычислении дисперсии является определение среднего значения выборки, которое в нашем примере равняется 7,8 раза в месяц. Остальные вычисления можно облегчить с помощью следующей таблицы.

Финальная фаза вычисления дисперсии выглядит так:
![]()
Для тех, кто любит производить все вычисления за один раз, уравнение будет выглядеть следующим образом:
Использование метода «сырого счета» (пример с готовкой)
Существует более эффективный способ вычисления дисперсии, известный как метод «сырого счета». Хотя с первого взгляда уравнение может показаться весьма громоздким, на самом деле оно не такое уж страшное. Можете в этом удостовериться, а потом и решите, какой метод вам больше нравится.

— сумма каждого значения данных после возведения в квадрат,
— квадрат суммы всех значений данных.
Не теряйте рассудок прямо сейчас. Позвольте представить все это в виде таблицы, и тогда вы увидите, что вычислений здесь меньше, чем в предыдущем примере.


Как видите, результат получился тот же, что и при использовании предыдущего метода. Достоинства данного метода становятся очевидными по мере роста размера выборки (n).
Расчет дисперсии в Excel
Как вы уже, наверное, догадались, в Excel присутствует формула, позволяющая рассчитать дисперсию. Причем, начиная с Excel 2010 можно найти 4 разновидности формулы дисперсии:
1) ДИСП.В – Возвращает дисперсию по выборке. Логические значения и текст игнорируются.
2) ДИСП.Г — Возвращает дисперсию по генеральной совокупности. Логические значения и текст игнорируются.
3) ДИСПА — Возвращает дисперсию по выборке с учетом логических и текстовых значений.
4) ДИСПРА — Возвращает дисперсию по генеральной совокупности с учетом логических и текстовых значений.
Для начала разберемся в разнице между выборкой и генеральной совокупностью. Назначение описательной статистики состоит в том, чтобы суммировать или отображать данные так, чтобы оперативно получать общую картину, так сказать, обзор. Статистический вывод позволяет делать умозаключения о какой-либо совокупности на основе выборки данных из этой совокупности. Совокупность представляет собой все возможные исходы или измерения, представляющие для нас интерес. Выборка — это подмножество совокупности.
Например, нас интересует совокупность группы студентов одного из Российских ВУЗов и нам необходимо определить средний бал группы. Мы можем посчитать среднюю успеваемость студентов, и тогда полученная цифра будет параметром, поскольку в наших расчетах будет задействована целая совокупность. Однако, если мы хотим рассчитать средний бал всех студентов нашей страны, тогда эта группа будет нашей выборкой.
Разница в формуле расчета дисперсии между выборкой и совокупностью заключается в знаменателе. Где для выборки он будет равняться (n-1), а для генеральной совокупности только n.
Теперь разберемся с функциями расчета дисперсии с окончаниями А, в описании которых сказано, что при расчете учитываются текстовые и логические значения. В данном случае при расчете дисперсии определенного массива данных, где встречаются не числовые значения, Excel будет интерпретировать текстовые и ложные логические значения как равными 0, а истинные логические значения как равными 1.
Итак, если у вас есть массив данных, рассчитать его дисперсию ни составит никакого труда, воспользовавшись одной из перечисленных выше функций Excel.

В случае, если совокупность разбита на группы по изучаемому признаку, то для данной совокупности могут быть исчислены следующие виды дисперсии: общая, групповые (внутригрупповые), средняя из групповых (средняя из внутригрупповых), межгрупповая.
Первоначально рассчитывает коэффициент детерминации, который показывает какую часть общей вариации изучаемого признака составляет вариация межгрупповая, т.е. обусловленная группировочным признаком:
Эмпирическое корреляционное отношение характеризует тесноту связи между признаками группировочным (факторным) и результативным.
Эмпирическое корреляционное отношение может принимать значения от 0 до 1.
Для оценки тесноты связи на основе показателя эмпирического корреляционного отношения можно воспользоваться соотношениями Чеддока:
Пример 4. Имеются следующие данные о выполнении работ проектно-изыскательскими организациями разной формы собственности:
Определить:
1) общую дисперсию;
2) групповые дисперсии;
3) среднюю из групповых дисперсий;
4) межгрупповую дисперсию;
5) общую дисперсию на основе правила сложения дисперсий;
6) коэффициент детерминации и эмпирическое корреляционное отношение.
Сделайте выводы.
Решение:
1. Определим средний объём выполнения работ предприятий двух форм собственности:
Рассчитаем общую дисперсию:
![]()
2. Определим групповые средние:
![]() млн руб.;
млн руб.;
![]() млн руб.
млн руб.
Групповые дисперсии:
![]() ;
;
3. Рассчитаем среднюю из групповых дисперсий:
4. Определим межгрупповую дисперсию:
5. Рассчитаем общую дисперсию на основе правила сложения дисперсий:
6. Определим коэффициент детерминации:
![]() .
.
Таким образом, объём работ, выполненных проектно-изыскательскими организациями на 22% зависит от формы собственности предприятий.
Эмпирическое корреляционное отношение рассчитываем по формуле
![]() .
.
Величина рассчитанного показателя свидетельствует о том, что зависимость объема работ от формы собственности предприятия невелика.
Пример 5. В результате обследования технологической дисциплины производственных участков получены следующие данные:
Определите коэффициент детерминации



