Solution.
As a measure of the dispersion of values random variable used dispersion
Dispersion (the word dispersion means “scattering”) is measure of dispersion of random variable values regarding her mathematical expectation. Dispersion is the mathematical expectation of the squared deviation of a random variable from its mathematical expectation
If the random variable is discrete with an infinite but countable set of values, then
if the series on the right side of the equality converges.
Properties of dispersion.
- 1. The variance of a constant value is zero
- 2. The variance of the sum of random variables is equal to the sum of the variances
- 3. The constant factor can be taken out of the sign of the squared dispersion
The variance of the difference of random variables is equal to the sum of the variances
This property is a consequence of the second and third properties. Variances can only add up.
It is convenient to calculate the dispersion using a formula that can be easily obtained using the properties of dispersion
Variance is always positive.
The variance has dimension squared dimension of the random variable itself, which is not always convenient. Therefore, the quantity
Standard deviation(standard deviation or standard) of a random variable is the arithmetic value of the square root of its variance
Throw two coins in denominations of 2 and 5 rubles. If the coin lands as a coat of arms, then zero points are awarded, and if it lands as a number, then the number of points equal to the denomination of the coin. Find the mathematical expectation and variance of the number of points.
Solution. Let us first find the distribution of the random variable X - the number of points. All combinations - (2;5),(2;0),(0;5),(0;0) - are equally probable and the distribution law is:

Mathematical expectation:
We find the variance using the formula
why do we calculate
Example 2.
Find unknown probability r, mathematical expectation and variance of a discrete random variable specified by a probability distribution table
We find the mathematical expectation and variance:
M(X) = 00,0081 + 10,0756 + 20,2646 + 3 0,4116 + +40,2401=2,8
To calculate the dispersion, we use formula (19.4)
D(X) = 020 ,0081 + 120,0756 + 220,2646 + 320,4116 + 420,2401 - 2,82 = 8,68 -

Example 3. Two equally strong athletes hold a tournament that lasts either until the first victory of one of them, or until five games have been played. The probability of winning one game for each of the athletes is 0.3, and the probability of a draw is 0.4. Find the distribution law, mathematical expectation and dispersion of the number of games played.
Solution. Random variable X- the number of games played, takes values from 1 to 5, i.e.
Let's determine the probabilities of ending the match. The match will end on the first set if one of their athletes wins. The probability of winning is
R(1) = 0,3+0,3 =0,6.
If there was a draw (the probability of a draw is 1 - 0.6 = 0.4), then the match continues. The match will end in the second game if the first was a draw and someone won the second. Probability
R(2) = 0,4 0,6=0,24.
Likewise, the match will end on the third game if there were two draws in a row and again someone won
R(3) = 0,4 0,4 0,6 = 0,096. R(4)= 0,4 0,4 0,4 0,6=0,0384.
The fifth game is the last in any version.
R(5)= 1 - (R(1)+R(2)+R(3)+R(4)) = 0,0256.
Let's put everything in a table. The distribution law of the random variable “number of games won” has the form
Expectation
We calculate the variance using formula (19.4)
Standard discrete distributions.
Binomial distribution. Let Bernoulli's experimental scheme be implemented: n identical independent experiments, in each of which the event A may appear with constant probability p and will not appear with probability
(see lecture 18).
Number of occurrences of the event A in these n experiments there is a discrete random variable X, the possible values of which are:
0; 1; 2; ... ;m; ... ; n.
Probability of appearance m events A in a specific series of n experiments with and the distribution law of such a random variable is given by the Bernoulli formula (see lecture 18)
 |



Numerical characteristics of a random variable X distributed according to the binomial law:

If n is great (), then, when, formula (19.6) goes into the formula
and the tabulated Gaussian function (the table of values of the Gaussian function is given at the end of lecture 18).
In practice, what is often important is not the probability of occurrence itself. m events A in a specific series from n experiments, and the probability that the event A no less will appear
times and no more than times, i.e. the probability that X takes the values
To do this, we need to sum up the probabilities
If n is great (), then, when, formula (19.9) turns into an approximate formula

tabulated function. The tables are given at the end of Lecture 18.
When using tables, it is necessary to take into account that
Example 1. A car approaching an intersection can continue moving along any of three roads: A, B or C with equal probability. Five cars approach the intersection. Find the average number of cars that will travel on road A and the probability that three cars will travel on road B.
Solution. The number of cars passing on each road is a random variable. If we assume that all cars approaching the intersection travel independently of each other, then this random variable is distributed according to the binomial law with
n= 5 and p = .
Therefore, the average number of cars that will follow road A is according to formula (19.7)
and the desired probability at
Example 2. The probability of device failure during each test is 0.1. 60 tests of the device are carried out. What is the probability that a device failure will occur: a) 15 times; b) no more than 15 times?
A. Since the number of tests is 60, we use formula (19.8)
According to table 1 of the appendix to lecture 18 we find
b. We use formula (19.10).
According to table 2 of the appendix to lecture 18
- - 0,495
- 0,49995
Poisson distribution) law of rare events). If n big and r little (), and the product pr retains a constant value, which we denote by l,
then formula (19.6) becomes Poisson’s formula

The Poisson distribution law has the form:

Obviously, the definition of Poisson's law is correct, because main property of a distribution series
Done, because sum of series
The series expansion of the function at
Theorem. The mathematical expectation and variance of a random variable distributed according to Poisson’s law coincide and are equal to the parameter of this law, i.e.
Proof.
Example. To promote its products on the market, the company lays out mailboxes flyers. Previous experience shows that in approximately one case out of 2,000 an order follows. Find the probability that when placing 10,000 advertisements, at least one order will arrive, the average number of orders received, and the variance of the number of orders received.
Solution. Here
We will find the probability that at least one order will arrive through the probability of the opposite event, i.e.
Random flow of events. A stream of events is a sequence of events that occur at random times. Typical examples of flows are failures in computer networks, calls at telephone exchanges, a flow of requests for equipment repairs, etc.
Flow events is called stationary, if the probability of a particular number of events falling into a time interval of length depends only on the length of the interval and does not depend on the location of the time interval on the time axis.
The stationarity condition is satisfied by a flow of requests whose probabilistic characteristics do not depend on time. In particular, a stationary flow is characterized by a constant density (the average number of requests per unit of time). In practice, there are often flows of requests that (at least for a limited period of time) can be considered stationary. For example, the flow of calls at a city telephone exchange in the time period from 12 to 13 hours can be considered landline. The same flow over the course of a whole day can no longer be considered stationary (at night the call density is significantly less than during the day).
Flow events is called a stream with no aftereffect, if for any non-overlapping time periods the number of events falling on one of them does not depend on the number of events falling on the others.
The condition of absence of aftereffect - the most essential for the simplest flow - means that applications enter the system independently of each other. For example, a flow of passengers entering a metro station can be considered a flow without aftereffects because the reasons that determined the arrival of an individual passenger at one particular moment and not another are, as a rule, not related to similar reasons for other passengers. However, the condition of no aftereffect can be easily violated due to the appearance of such a dependence. For example, the flow of passengers leaving a metro station can no longer be considered a flow without aftereffect, since the exit moments of passengers arriving on the same train are dependent on each other.
Flow events is called ordinary, if the probability of two or more events occurring within a short time interval t is negligible compared to the probability of one event occurring (in this regard, Poisson’s law is called the law of rare events).
The ordinariness condition means that orders arrive singly, and not in pairs, triplets, etc. variance deviation Bernoulli distribution
For example, the flow of customers entering a hairdressing salon can be considered almost ordinary. If in an extraordinary flow applications arrive only in pairs, only in triplets, etc., then the extraordinary flow can easily be reduced to an ordinary one; To do this, it is enough to consider a stream of pairs, triplets, etc. instead of a stream of individual requests. It will be more difficult if each request can randomly turn out to be double, triple, etc. Then you have to deal with a stream of not homogeneous, but heterogeneous events.
If a stream of events has all three properties (i.e., stationary, ordinary, and has no aftereffect), then it is called a simple (or stationary Poisson) stream. The name "Poisson" is due to the fact that if the listed conditions are met, the number of events falling on any fixed time interval will be distributed over Poisson's law
Here is the average number of events A, appearing per unit of time.
This law is one-parameter, i.e. to set it, you only need to know one parameter. It can be shown that the expectation and variance in Poisson's law are numerically equal:
Example. Let's say that in the middle of the working day the average number of requests is 2 per second. What is the probability that 1) no applications will be received in a second, 2) 10 applications will arrive in two seconds?
Solution. Since the validity of the application of Poisson’s law is beyond doubt and its parameter is given (= 2), the solution of the problem is reduced to the application of Poisson’s formula (19.11)
1) t = 1, m = 0:
2) t = 2, m = 10:
Law large numbers. The mathematical basis for the fact that the values of a random variable cluster around some constant values is the law of large numbers.
Historically, the first formulation of the law of large numbers was Bernoulli’s theorem:
“With an unlimited increase in the number of identical and independent experiments n, the frequency of occurrence of event A converges in probability to its probability,” i.e.
where is the frequency of occurrence of event A in n experiments,
In essence, expression (19.10) means that when large number experiments frequency of occurrence of an event A can replace the unknown probability of this event, and the greater the number of experiments performed, the closer p* to p. Interesting historical fact. K. Pearson tossed a coin 12,000 times and his coat of arms came up 6,019 times (frequency 0.5016). When throwing the same coin 24,000 times, he got 12,012 coats of arms, i.e. frequency 0.5005.
The most important form of the law of large numbers is Chebyshev's theorem: with an unlimited increase in the number of independent experiments having finite variance and conducted under identical conditions, the arithmetic mean of the observed values of the random variable converges in probability to its mathematical expectation. In analytical form, this theorem can be written as follows:
In addition to fundamental theoretical significance, Chebyshev's theorem also has important practical applications, for example, in measurement theory. After taking n measurements of a certain quantity X, get different non-matching values X 1, X 2, ..., xn. For the approximate value of the measured quantity X take the arithmetic mean of the observed values
At the same time, The more experiments are carried out, the more accurate the result will be. The fact is that the dispersion of the quantity decreases with an increase in the number of experiments performed, because
D(x 1) = D(x 2)=…= D(xn) D(x) , That
Relationship (19.13) shows that even with high inaccuracy of measuring instruments (large value), by increasing the number of measurements, it is possible to obtain a result with arbitrarily high accuracy.
Using formula (19.10) you can find the probability that the statistical frequency deviates from the probability by no more than


Example. The probability of an event in each trial is 0.4. How many tests do you need to carry out in order to expect, with a probability of no less than 0.8, that the relative frequency of an event will deviate from the absolute probability by less than 0.01?
Solution. According to formula (19.14)


therefore, according to the table there are two applications
hence, n 3932.
Probability theory is a special branch of mathematics that is studied only by students of higher educational institutions. Do you like calculations and formulas? Aren't you scared by the prospects of getting acquainted with the normal distribution, ensemble entropy, mathematical expectation and dispersion of a discrete random variable? Then this subject will be very interesting to you. Let's get acquainted with several of the most important basic concepts of this branch of science.
Let's remember the basics
Even if you remember the most simple concepts theory of probability, do not neglect the first paragraphs of the article. The point is that without a clear understanding of the basics, you will not be able to work with the formulas discussed below.
So, some random event occurs, some experiment. As a result of the actions we take, we can get several outcomes - some of them occur more often, others less often. The probability of an event is the ratio of the number of actually obtained outcomes of one type to total number possible. Only knowing the classical definition of this concept can you begin to study the mathematical expectation and dispersion of continuous random variables.
Arithmetic mean
Back in school, during math lessons, you started working with the arithmetic mean. This concept is widely used in probability theory, and therefore cannot be ignored. The main thing for us is at the moment is that we will encounter it in the formulas for the mathematical expectation and dispersion of a random variable.

We have a sequence of numbers and want to find the arithmetic mean. All that is required of us is to sum up everything available and divide by the number of elements in the sequence. Let us have numbers from 1 to 9. The sum of the elements will be equal to 45, and we will divide this value by 9. Answer: - 5.
Dispersion
In scientific terms, dispersion is the average square of deviations of the obtained values of a characteristic from the arithmetic mean. It is denoted by one capital Latin letter D. What is needed to calculate it? For each element of the sequence, we calculate the difference between the existing number and the arithmetic mean and square it. There will be exactly as many values as there can be outcomes for the event we are considering. Next, we sum up everything received and divide by the number of elements in the sequence. If we have five possible outcomes, then divide by five.

Dispersion also has properties that need to be remembered in order to be used when solving problems. For example, when a random variable increases by X times, the variance increases by X squared times (i.e. X*X). She never happens less than zero and does not depend on shifting values by an equal value up or down. Additionally, for independent trials, the variance of the sum is equal to the sum of the variances.
Now we definitely need to consider examples of the dispersion of a discrete random variable and the mathematical expectation.
Let's say we ran 21 experiments and got 7 different outcomes. We observed each of them 1, 2, 2, 3, 4, 4 and 5 times, respectively. What will the variance be equal to?
First, let's calculate the arithmetic mean: the sum of the elements, of course, is 21. Divide it by 7, getting 3. Now subtract 3 from each number in the original sequence, square each value, and add the results together. The result is 12. Now all we have to do is divide the number by the number of elements, and, it would seem, that’s all. But there's a catch! Let's discuss it.
Dependence on the number of experiments
It turns out that when calculating variance, the denominator can contain one of two numbers: either N or N-1. Here N is the number of experiments performed or the number of elements in the sequence (which is essentially the same thing). What does this depend on?

If the number of tests is measured in hundreds, then we must put N in the denominator. If in units, then N-1. Scientists decided to draw the border quite symbolically: today it passes through the number 30. If we conducted less than 30 experiments, then we will divide the amount by N-1, and if more, then by N.
Task
Let's return to our example of solving the problem of variance and mathematical expectation. We got an intermediate number 12, which needed to be divided by N or N-1. Since we conducted 21 experiments, which is less than 30, we will choose the second option. So the answer is: the variance is 12 / 2 = 2.
Expectation
Let's move on to the second concept, which we must consider in this article. The mathematical expectation is the result of adding all possible outcomes multiplied by the corresponding probabilities. It is important to understand that the obtained value, as well as the result of calculating the variance, is obtained only once for the whole task, no matter how many outcomes are considered.

The formula for mathematical expectation is quite simple: we take the outcome, multiply by its probability, add the same for the second, third result, etc. Everything related to this concept is not difficult to calculate. For example, the sum of the expected values is equal to the expected value of the sum. The same is true for the work. Not every quantity in probability theory allows you to perform such simple operations. Let's take the problem and calculate the meaning of two concepts we have studied at once. Besides, we were distracted by theory - it's time to practice.
Another example
We ran 50 trials and got 10 types of outcomes - numbers from 0 to 9 - appearing in different percentages. These are, respectively: 2%, 10%, 4%, 14%, 2%,18%, 6%, 16%, 10%, 18%. Recall that to obtain probabilities, you need to divide the percentage values by 100. Thus, we get 0.02; 0.1, etc. Let us present an example of solving the problem for the variance of a random variable and the mathematical expectation.
We calculate the arithmetic mean using the formula that we remember from elementary school: 50/10 = 5.
Now let’s convert the probabilities into the number of outcomes “in pieces” to make it easier to count. We get 1, 5, 2, 7, 1, 9, 3, 8, 5 and 9. From each value obtained, we subtract the arithmetic mean, after which we square each of the results obtained. See how to do this using the first element as an example: 1 - 5 = (-4). Next: (-4) * (-4) = 16. For other values, do these operations yourself. If you did everything correctly, then after adding them all up you will get 90.

Let's continue calculating the variance and expected value by dividing 90 by N. Why do we choose N rather than N-1? Correct, because the number of experiments performed exceeds 30. So: 90/10 = 9. We got the variance. If you get a different number, don't despair. Most likely, you made a simple mistake in the calculations. Double-check what you wrote, and everything will probably fall into place.
Finally, remember the formula for mathematical expectation. We will not give all the calculations, we will only write an answer that you can check with after completing all the required procedures. The expected value will be 5.48. Let us only recall how to carry out operations, using the first elements as an example: 0*0.02 + 1*0.1... and so on. As you can see, we simply multiply the outcome value by its probability.
Deviation
Another concept closely related to dispersion and mathematical expectation is standard deviation. It is designated either in Latin letters sd, or Greek lowercase "sigma". This concept shows how much on average the values deviate from the central feature. To find its value, you need to calculate square root from dispersion.

If you plot a normal distribution graph and want to see the squared deviation directly on it, this can be done in several stages. Take half of the image to the left or right of the mode (central value), draw a perpendicular to the horizontal axis so that the areas of the resulting figures are equal. The size of the segment between the middle of the distribution and the resulting projection onto the horizontal axis will represent the standard deviation.
Software
As can be seen from the descriptions of the formulas and the examples presented, calculating variance and mathematical expectation is not the simplest procedure from an arithmetic point of view. In order not to waste time, it makes sense to use the program used in higher education educational institutions- it's called "R". It has functions that allow you to calculate values for many concepts from statistics and probability theory.
For example, you specify a vector of values. This is done as follows: vector<-c(1,5,2…). Теперь, когда вам потребуется посчитать какие-либо значения для этого вектора, вы пишете функцию и задаете его в качестве аргумента. Для нахождения дисперсии вам нужно будет использовать функцию var. Пример её использования: var(vector). Далее вы просто нажимаете «ввод» и получаете результат.
In conclusion
Dispersion and mathematical expectation are without which it is difficult to calculate anything in the future. In the main course of lectures at universities, they are discussed already in the first months of studying the subject. It is precisely because of the lack of understanding of these simple concepts and the inability to calculate them that many students immediately begin to fall behind in the program and later receive bad grades at the end of the session, which deprives them of scholarships.
Practice for at least one week, half an hour a day, solving tasks similar to those presented in this article. Then, on any test in probability theory, you will be able to cope with the examples without extraneous tips and cheat sheets.
The variance of a random variable is a measure of the spread of the values of this variable. Low variance means that the values are clustered close together. Large dispersion indicates a strong spread of values. The concept of variance of a random variable is used in statistics. For example, if you compare the variance of two values (such as between male and female patients), you can test the significance of a variable. Variance is also used when building statistical models, since low variance can be a sign that you are overfitting the values.Steps
Calculating sample variance
-
Record the sample values. In most cases, statisticians only have access to samples of specific populations. For example, as a rule, statisticians do not analyze the cost of maintaining the totality of all cars in Russia - they analyze a random sample of several thousand cars. Such a sample will help determine the average cost of a car, but most likely the resulting value will be far from the real one.
- For example, let's analyze the number of buns sold in a cafe over 6 days, taken in random order. The sample looks like this: 17, 15, 23, 7, 9, 13. This is a sample, not a population, because we do not have data on buns sold for each day the cafe is open.
- If you are given a population rather than a sample of values, continue to the next section.
-
Write down a formula to calculate sample variance. Dispersion is a measure of the spread of values of a certain quantity. The closer the variance value is to zero, the closer the values are grouped together. When working with a sample of values, use the following formula to calculate variance:
- s 2 (\displaystyle s^(2)) = ∑[(x i (\displaystyle x_(i))- x̅) 2 (\displaystyle ^(2))] / (n - 1)
- s 2 (\displaystyle s^(2))– this is dispersion. Dispersion is measured in square units.
- x i (\displaystyle x_(i))– each value in the sample.
- x i (\displaystyle x_(i)) you need to subtract x̅, square it, and then add the results.
- x̅ – sample mean (sample mean).
- n – number of values in the sample.
-
Calculate the sample mean. It is denoted as x̅. The sample mean is calculated as a simple arithmetic mean: add up all the values in the sample, and then divide the result by the number of values in the sample.
- In our example, add the values in the sample: 15 + 17 + 23 + 7 + 9 + 13 = 84
Now divide the result by the number of values in the sample (in our example there are 6): 84 ÷ 6 = 14.
Sample mean x̅ = 14. - The sample mean is the central value around which the values in the sample are distributed. If the values in the sample cluster around the sample mean, then the variance is small; otherwise the variance is large.
- In our example, add the values in the sample: 15 + 17 + 23 + 7 + 9 + 13 = 84
-
Subtract the sample mean from each value in the sample. Now calculate the difference x i (\displaystyle x_(i))- x̅, where x i (\displaystyle x_(i))– each value in the sample. Each result obtained indicates the extent to which a particular value deviates from the sample mean, that is, how far this value is from the sample mean.
- In our example:
x 1 (\displaystyle x_(1))- x = 17 - 14 = 3
x 2 (\displaystyle x_(2))- x̅ = 15 - 14 = 1
x 3 (\displaystyle x_(3))- x = 23 - 14 = 9
x 4 (\displaystyle x_(4))- x̅ = 7 - 14 = -7
x 5 (\displaystyle x_(5))- x̅ = 9 - 14 = -5
x 6 (\displaystyle x_(6))- x̅ = 13 - 14 = -1 - The correctness of the results obtained is easy to check, since their sum should be equal to zero. This is related to the definition of the average, since negative values (distances from the average to smaller values) are completely offset by positive values (distances from the average to larger values).
- In our example:
-
As noted above, the sum of the differences x i (\displaystyle x_(i))- x̅ must be equal to zero. This means that the average variance is always zero, which does not give any idea about the spread of values of a certain quantity. To solve this problem, square each difference x i (\displaystyle x_(i))- x̅. This will result in you only getting positive numbers, which will never add up to 0.
- In our example:
(x 1 (\displaystyle x_(1))- x̅) 2 = 3 2 = 9 (\displaystyle ^(2)=3^(2)=9)
(x 2 (\displaystyle (x_(2))- x̅) 2 = 1 2 = 1 (\displaystyle ^(2)=1^(2)=1)
9 2 = 81
(-7) 2 = 49
(-5) 2 = 25
(-1) 2 = 1 - You found the square of the difference - x̅) 2 (\displaystyle ^(2)) for each value in the sample.
- In our example:
-
Calculate the sum of the squares of the differences. That is, find that part of the formula that is written like this: ∑[( x i (\displaystyle x_(i))- x̅) 2 (\displaystyle ^(2))]. Here the sign Σ means the sum of squared differences for each value x i (\displaystyle x_(i)) in the sample. You have already found the squared differences (x i (\displaystyle (x_(i))- x̅) 2 (\displaystyle ^(2)) for each value x i (\displaystyle x_(i)) in the sample; now just add these squares.
- In our example: 9 + 1 + 81 + 49 + 25 + 1 = 166 .
-
Divide the result by n - 1, where n is the number of values in the sample. Some time ago, to calculate sample variance, statisticians simply divided the result by n; in this case you will get the mean of the squared variance, which is ideal for describing the variance of a given sample. But remember that any sample is only a small part of the population of values. If you take another sample and perform the same calculations, you will get a different result. As it turns out, dividing by n - 1 (rather than just n) gives a more accurate estimate of the population variance, which is what you're interested in. Division by n – 1 has become common, so it is included in the formula for calculating sample variance.
- In our example, the sample includes 6 values, that is, n = 6.
Sample variance = s 2 = 166 6 − 1 = (\displaystyle s^(2)=(\frac (166)(6-1))=) 33,2
- In our example, the sample includes 6 values, that is, n = 6.
-
The difference between variance and standard deviation. Note that the formula contains an exponent, so the dispersion is measured in square units of the value being analyzed. Sometimes such a magnitude is quite difficult to operate; in such cases, use the standard deviation, which is equal to the square root of the variance. That is why the sample variance is denoted as s 2 (\displaystyle s^(2)), and the standard deviation of the sample is as s (\displaystyle s).
- In our example, the standard deviation of the sample is: s = √33.2 = 5.76.
Calculating Population Variance
-
Analyze some set of values. The set includes all values of the quantity under consideration. For example, if you are studying the age of residents of the Leningrad region, then the totality includes the age of all residents of this region. When working with a population, it is recommended to create a table and enter the population values into it. Consider the following example:
- In a certain room there are 6 aquariums. Each aquarium contains the following number of fish:
x 1 = 5 (\displaystyle x_(1)=5)
x 2 = 5 (\displaystyle x_(2)=5)
x 3 = 8 (\displaystyle x_(3)=8)
x 4 = 12 (\displaystyle x_(4)=12)
x 5 = 15 (\displaystyle x_(5)=15)
x 6 = 18 (\displaystyle x_(6)=18)
- In a certain room there are 6 aquariums. Each aquarium contains the following number of fish:
-
Write down a formula to calculate the population variance. Since the population includes all values of a certain quantity, the formula below allows you to obtain the exact value of the population variance. To distinguish population variance from sample variance (which is only an estimate), statisticians use various variables:
- σ 2 (\displaystyle ^(2)) = (∑(x i (\displaystyle x_(i)) - μ) 2 (\displaystyle ^(2)))/n
- σ 2 (\displaystyle ^(2))– population dispersion (read as “sigma squared”). Dispersion is measured in square units.
- x i (\displaystyle x_(i))– each value in its entirety.
- Σ – sum sign. That is, from each value x i (\displaystyle x_(i)) you need to subtract μ, square it, and then add the results.
- μ – population mean.
- n – number of values in the population.
-
Calculate the population mean. When working with a population, its mean is denoted as μ (mu). The population mean is calculated as a simple arithmetic mean: add up all the values in the population, and then divide the result by the number of values in the population.
- Keep in mind that averages are not always calculated as the arithmetic mean.
- In our example, the population mean: μ = 5 + 5 + 8 + 12 + 15 + 18 6 (\displaystyle (\frac (5+5+8+12+15+18)(6))) = 10,5
-
Subtract the population mean from each value in the population. The closer the difference is to zero, the closer the specific value is to the population mean. Find the difference between each value in the population and its mean, and you will get a first idea of the distribution of values.
- In our example:
x 1 (\displaystyle x_(1))- μ = 5 - 10.5 = -5.5
x 2 (\displaystyle x_(2))- μ = 5 - 10.5 = -5.5
x 3 (\displaystyle x_(3))- μ = 8 - 10.5 = -2.5
x 4 (\displaystyle x_(4))- μ = 12 - 10.5 = 1.5
x 5 (\displaystyle x_(5))- μ = 15 - 10.5 = 4.5
x 6 (\displaystyle x_(6))- μ = 18 - 10.5 = 7.5
- In our example:
-
Square each result obtained. The difference values will be both positive and negative; If these values are plotted on a number line, they will lie to the right and left of the population mean. This is not good for calculating variance because positive and negative numbers cancel each other out. So square each difference to get exclusively positive numbers.
- In our example:
(x i (\displaystyle x_(i)) - μ) 2 (\displaystyle ^(2)) for each population value (from i = 1 to i = 6):
(-5,5)2 (\displaystyle ^(2)) = 30,25
(-5,5)2 (\displaystyle ^(2)), Where x n (\displaystyle x_(n))– the last value in the population. - To calculate the average value of the results obtained, you need to find their sum and divide it by n:(( x 1 (\displaystyle x_(1)) - μ) 2 (\displaystyle ^(2)) + (x 2 (\displaystyle x_(2)) - μ) 2 (\displaystyle ^(2)) + ... + (x n (\displaystyle x_(n)) - μ) 2 (\displaystyle ^(2)))/n
- Now let's write down the above explanation using variables: (∑( x i (\displaystyle x_(i)) - μ) 2 (\displaystyle ^(2))) / n and get a formula for calculating the population variance.
- In our example:
If the population is divided into groups according to the characteristic being studied, then the following types of variance can be calculated for this population: total, group (within-group), average of group (average of within-group), intergroup.
Initially, it calculates the coefficient of determination, which shows what part of the total variation of the trait being studied is intergroup variation, i.e. due to the grouping characteristic:
The empirical correlation relationship characterizes the closeness of the connection between grouping (factorial) and performance characteristics.
The empirical correlation ratio can take values from 0 to 1.
To assess the closeness of the connection based on the empirical correlation ratio, you can use the Chaddock relations:
Example 4. The following data is available on the performance of work by design and survey organizations of various forms of ownership:
Define:
1) total variance;
2) group variances;
3) the average of the group variances;
4) intergroup variance;
5) total variance based on the rule for adding variances;
6) coefficient of determination and empirical correlation ratio.
Draw conclusions.
Solution:
1. Let us determine the average volume of work performed by enterprises of two forms of ownership:
Let's calculate the total variance:
![]()
2. Determine group averages:
![]() million rubles;
million rubles;
![]() million rubles
million rubles
Group variances:
![]() ;
;
3. Calculate the average of the group variances:
4. Let's determine the intergroup variance:
5. Calculate the total variance based on the rule for adding variances:
6. Let's determine the coefficient of determination:
![]() .
.
Thus, the volume of work performed by design and survey organizations depends by 22% on the form of ownership of the enterprises.
The empirical correlation ratio is calculated using the formula
![]() .
.
The value of the calculated indicator indicates that the dependence of the volume of work on the form of ownership of the enterprise is small.
Example 5. As a result of a survey of the technological discipline of production areas, the following data were obtained:
Determine the coefficient of determination
Along with studying the variation of a characteristic throughout the entire population as a whole, it is often necessary to trace quantitative changes in the characteristic across the groups into which the population is divided, as well as between groups. This study of variation is achieved by calculating and analyzing different types of variance.
There are total, intergroup and intragroup variances.
Total variance σ 2 measures the variation of a trait throughout the entire population under the influence of all factors that caused this variation.
Intergroup variance (δ) characterizes systematic variation, i.e. differences in the value of the studied trait that arise under the influence of the factor trait that forms the basis of the group. It is calculated using the formula: 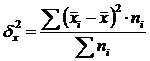 .
.
Within-group variance (σ) reflects random variation, i.e. part of the variation that occurs under the influence of unaccounted factors and does not depend on the factor-attribute that forms the basis of the group. It is calculated by the formula: 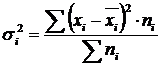 .
.
Average of within-group variances:  .
.
There is a law connecting 3 types of dispersion. The total variance is equal to the sum of the average of the within-group and between-group variance: ![]() .
.
This ratio is called rule for adding variances.
A widely used indicator in analysis is the proportion of between-group variance in the total variance. It's called empirical coefficient of determination (η 2): .
The square root of the empirical coefficient of determination is called empirical correlation ratio (η):
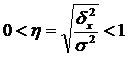 .
.
It characterizes the influence of the characteristic that forms the basis of the group on the variation of the resulting characteristic. The empirical correlation ratio ranges from 0 to 1.
Let us demonstrate its practical use using the following example (Table 1).
Example No. 1. Table 1 - Labor productivity of two groups of workers in one of the workshops of NPO Cyclone
Let's calculate the overall and group means and variances:
The initial data for calculating the average of intragroup and intergroup variance are presented in table. 2.
Table 2
Calculation and δ 2 for two groups of workers.
|
Worker groups | Number of workers, people | Average, children/shift | Dispersion |
| Completed technical training | 5 | 95 | 42,0 |
| Those who have not completed technical training | 5 | 81 | 231,2 |
| All workers | 10 | 88 | 185,6 |
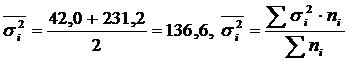 .
.
Intergroup variance
Total variance:
Thus, the empirical correlation ratio: .
Along with variation in quantitative characteristics, variation in qualitative characteristics can also be observed. This study of variation is achieved by calculating the following types of variances:
The within-group dispersion of the share is determined by the formula
Where n i– number of units in separate groups.The share of the studied characteristic in the entire population, which is determined by the formula:
The three types of variance are related to each other as follows:
This relation of variances is called the theorem of addition of variances of the trait share.



